

Reading time: 4 min read
In this issue:
💡 The crisis management framework that saved a client relationship
🔥 Why systematic thinking beats technical heroics in deployment disasters
✅ 3 leadership decisions you can apply to any technology crisis
The call came at 11:47 PM on a Tuesday. Our mobile AI platform was supposed to launch company-wide in 72 hours. Six months of development. Everything worked perfectly on iPhones, but every single Android device crashed within 30 seconds.
My team was panicking. The client was asking questions I couldn't answer. And I had to decide: Do we delay the launch, risk the contract, and admit failure? Or do we find a way to deliver?
72 hours later, we deployed flawlessly across both platforms with 99.8% uptime. The client renewed for another year. But the real victory wasn't technical—it was learning how to lead through a crisis that could have destroyed our credibility.
Here's the leadership framework that turned potential disaster into operational excellence.
Crisis Leadership: The First 2 Hours Matter Most
When your technology fails at the worst possible moment, your first instinct is to throw more developers at the problem. I almost made that mistake.
Instead, I spent the first 2 hours not coding, but thinking strategically:
Stakeholder Communication Strategy:
Client update in 6 hours with a realistic timeline
Team accountability without blame assignment
Resource allocation based on impact, not urgency
Risk Assessment Framework:
What's the maximum downside if we delay?
What's the cost of rushing and failing again?
Where can we cut scope without compromising core value?
Decision Matrix:
Technical resources available vs. time remaining
Client relationship impact of different scenarios
Long-term reputation consequences
The breakthrough insight: This wasn't a technical problem; it was a business risk management problem that happened to involve technology.
📌 SAVE THIS: "In a crisis, your first decision determines whether you're managing the problem or the problem is managing you."
The Lesson in Systematic Thinking
My team wanted to work around the clock, trying random solutions. I made the harder choice: Step back and build a systematic approach.
The methodology that worked:
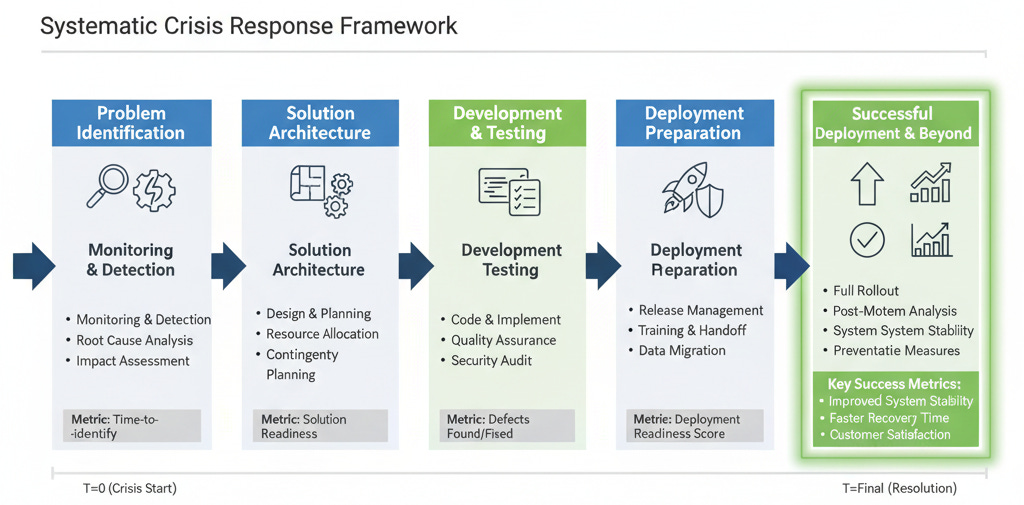
Phase 1: Problem Definition (4 hours)
Document exactly what worked and what didn't
Identify the precise failure points
Map dependencies and potential cascade effects
Phase 2: Solution Architecture (8 hours)
Design fixes for root causes, not symptoms
Build testing protocols to prevent regression
Create deployment verification checkpoints
Phase 3: Execution & Validation (60 hours)
Implement solutions in order of business impact
Test extensively before touching production
Maintain client communication at every milestone
Business Impact:
Before the systematic approach: Team working 16-hour days with diminishing returns
After framework implementation: Focused 8-hour days with measurable progress
Morale transformation: From panic to confidence in 24 hours
The Hidden Cost of Technical Debt
This crisis revealed something crucial: The failure wasn't caused by bad technology—accumulated shortcuts caused it.
Over six months, small compromises had built up:
Skipped testing protocols to meet sprint deadlines
Platform-specific issues deferred to "later"
Build system optimizations postponed repeatedly
ROI of Systematic Approach:
Crisis contained: 72 hours vs. projected 2-3 weeks
Client confidence maintained: Contract renewed
Team capability improved: 40% faster deployment cycles going forward
Prevented future failures: Estimated $50,000+ in avoided crisis costs
This wasn't just about fixing a bug; it was about proving we could deliver under pressure and build systems that don't break at the worst possible moment.
Leadership Under Pressure: What I Learned
The Counter-Intuitive Moves That Worked:
1. Slowing Down to Speed Up. While my team wanted to code frantically, I insisted on 2 hours of planning first. That planning saved us 20+ hours of wasted effort.
2. Transparent Communication I told the client precisely what happened and our recovery plan. Instead of losing confidence, they appreciated the honesty and systematic response.
3. Process Over Heroics Rather than celebrating the developers who worked all night, I recognized the ones who built reusable testing protocols that prevented future failures.
The Executive Lesson: Your team's technical capabilities matter less than your ability to make good decisions under pressure and build systems that scale.

The Framework: Crisis to Capability
Here's the leadership playbook that works for any technology crisis:
Hour 1-2: Strategic Assessment
Resist the urge to jump into tactical solutions
Map all stakeholders and communication requirements
Define success criteria and acceptable trade-offs
Hour 3-8: Resource Optimization
Allocate your best people to root cause analysis
Set up systematic testing and validation processes
Establish a regular stakeholder update schedule
Hour 9+: Systematic Execution
Fix root causes, not symptoms
Document everything for future prevention
Maintain team morale through visible progress
Monday Morning Test
How to prepare for your next technology crisis:
Audit your technical debt: What shortcuts are accumulating risk in your systems?
Build crisis communication protocols: Who needs updates, when, and in what format?
Practice systematic problem-solving: Train your team to diagnose before prescribing solutions
The Meta-Lesson for AI Leaders
Every AI deployment will face moments like this. The technology will fail at the worst possible time. Stakeholders will panic. Your team will want to throw heroic effort at the problem.
Your job as a leader isn't to be the best debugger—it's to make the decisions that turn technical problems into business capabilities.
The companies that scale AI successfully aren't the ones with the fewest failures. They're the ones that build systematic approaches to turning failures into competitive advantages.
The strategic insight: Great AI leadership requires operational excellence. You can have the most intelligent algorithms in the world, but if you can't deploy and maintain them reliably under pressure, none of that intelligence creates business value.
Ready to build crisis-resilient AI systems? The systematic approach that saved this deployment is now part of our enterprise AI operational framework. Let's discuss how this methodology can strengthen your organization's technology resilience.