
Self healing Claude
The four-step pattern that keeps a 15-agent fleet from quietly going sideways

Tuesday morning, coffee in hand, scanning my agent fleet’s overnight reports. The Family CFO’s expense summary was off. One row in twenty, a date it had parsed cleanly for months, suddenly misread. Nothing had alerted. Nothing had broken. The Chief of Staff had quietly started returning summaries shaped a little differently than the week before, too. When I finally traced it, the drift went back six weeks, to a couple of two-sentence edits I’d made to my CLAUDE.md files and long since forgotten.
Across 15+ Claude Code agents I run in production, the dangerous edits are never the architectural ones. Those get reviewed. The dangerous edits are the two-sentence clarifications you make in twenty seconds between meetings, the ones that look identical to the last edit and contradict a rule three sections higher. Your CLAUDE.md isn’t wrong. It’s just not defending itself.
This Build Log is the pattern I use to stop that. A CLAUDE.md that watches itself, diagnoses drift, proposes a fix, and waits for me to confirm. I call it the Detect → Diagnose → Propose → Confirm loop, or DDPC for short.
The Problem: Drift You Can’t See Until It’s Expensive
Here are the specific edits that caused it.
Six weeks ago, I added a small clause to the CLAUDE.md for my content-system project. Two sentences about how to handle ClickHouse-related posts. A week later, I added another small clause to my Chief of Staff agent’s CLAUDE.md, about how to format calendar summaries. Tiny edits. Routine.
Both were correct in isolation. Both were wrong in aggregate. The content-system clause changed the tone definition in a way that contradicted a rule three sections higher. The Chief of Staff clause introduced a date format that conflicted with the date format the Family CFO agent expected when reading the same calendar exports.
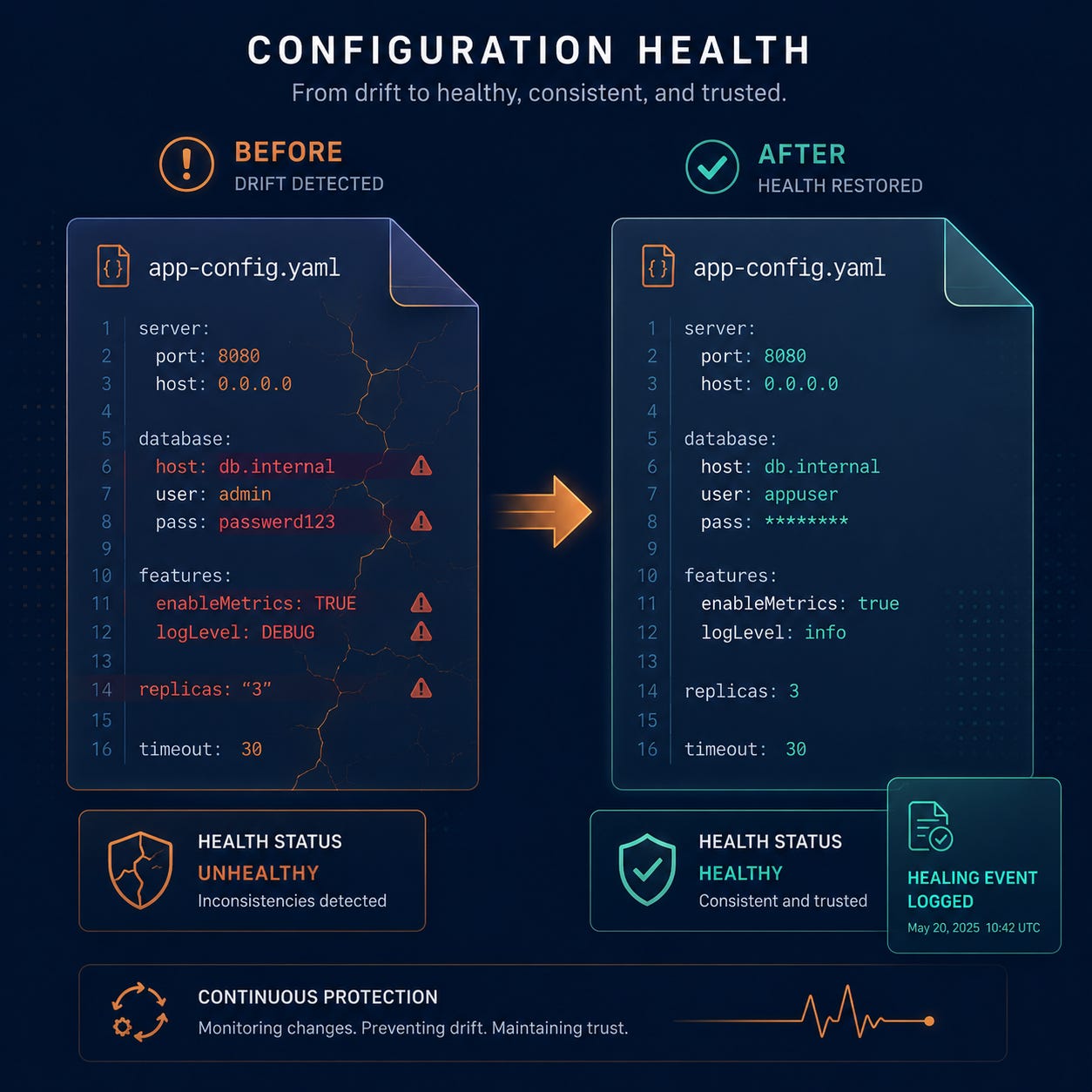
The agents didn’t fail. They drifted. The content system started using a tone that wasn’t quite the tone in PERSONA.md. The Family CFO miscount kept growing in the background. None of these were errors. They were all silent regressions. Drift compounds in the gaps between sections.
For a CTO, here is what this means: every CLAUDE.md edit is a deploy. You wouldn’t ship a code change without a test suite. You shouldn’t ship a config change without a consistency check. The reason teams don’t is that the tooling didn’t exist. So I built it.
The Failed First Approach: Pre-Commit Lint
My first attempt was the obvious one: a pre-commit hook that linted CLAUDE.md.
I wrote a Python script that ran on every commit touching a CLAUDE.md file. It checked for a fixed list of structural issues: missing required sections, duplicate headers, broken internal links to other markdown files in the repo, sections that exceeded a maximum word count. It would block the commit if any of those tripped.
It worked. Sort of. For about three weeks.
Then I noticed the hook was catching almost nothing. Not because the configs were getting better. Because the actual drift wasn’t structural. It was semantic. A section labeled “Voice” said the tone was “direct and warm.” Another section labeled “Examples” had a sample that read as flippant. Both were syntactically fine. The lint hook had nothing to say.
The lesson: a checker that only understands structure cannot catch a configuration whose damage is in meaning. CLAUDE.md is not code. It is a document the agent reads as instruction. The checker needs to read it the same way the agent does.
That meant the checker had to be an LLM. Which meant the checker had to be governed, because now the checker itself could drift, hallucinate fixes, or propose changes that quietly broke things. The architecture had to assume the diagnostician was fallible.
This is where the design started over.
The Better Solution: A Self-Healing Loop With a Hard Boundary
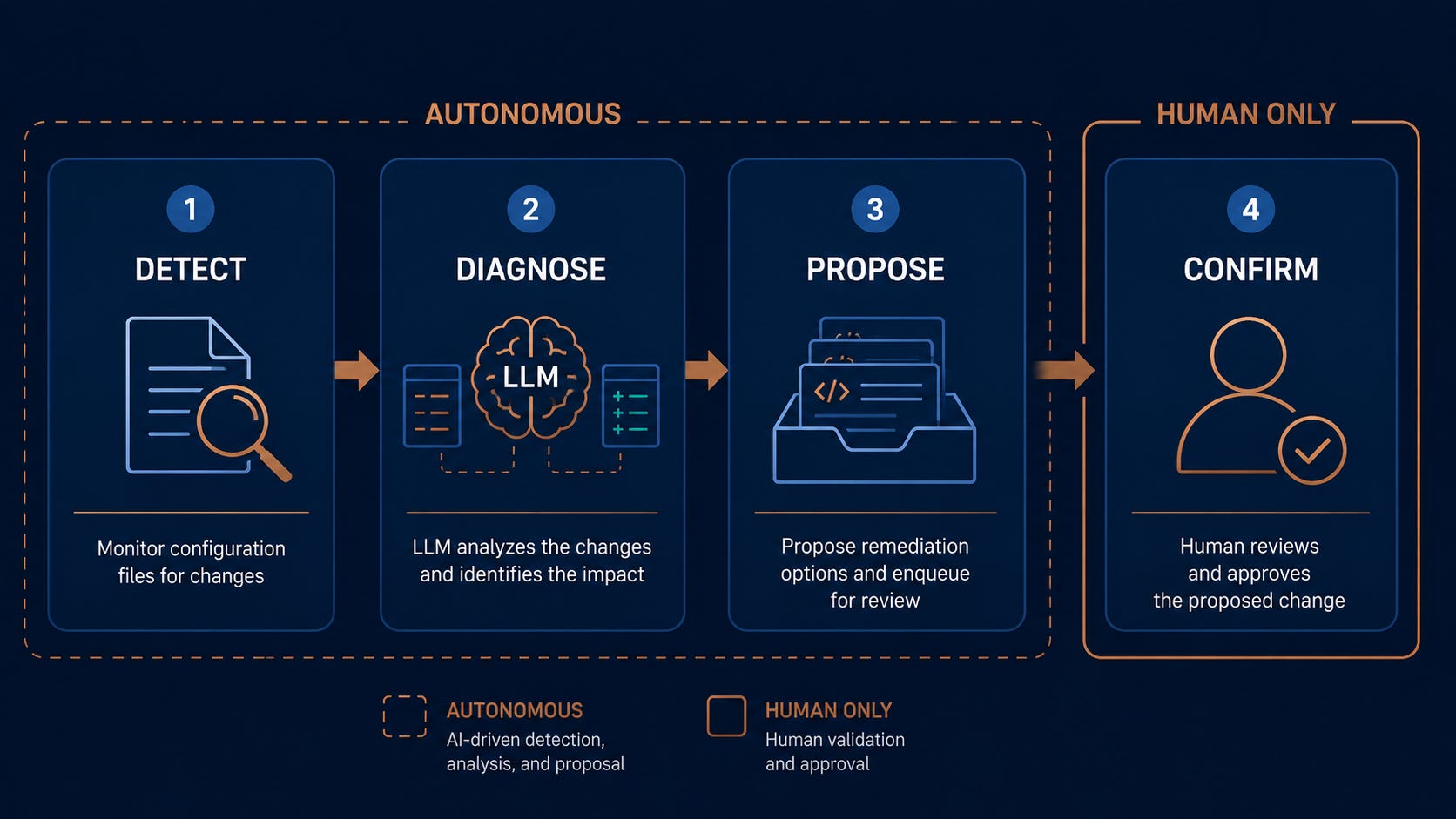
The architecture I settled on has four stages, each with a clear input, output, and authority level.
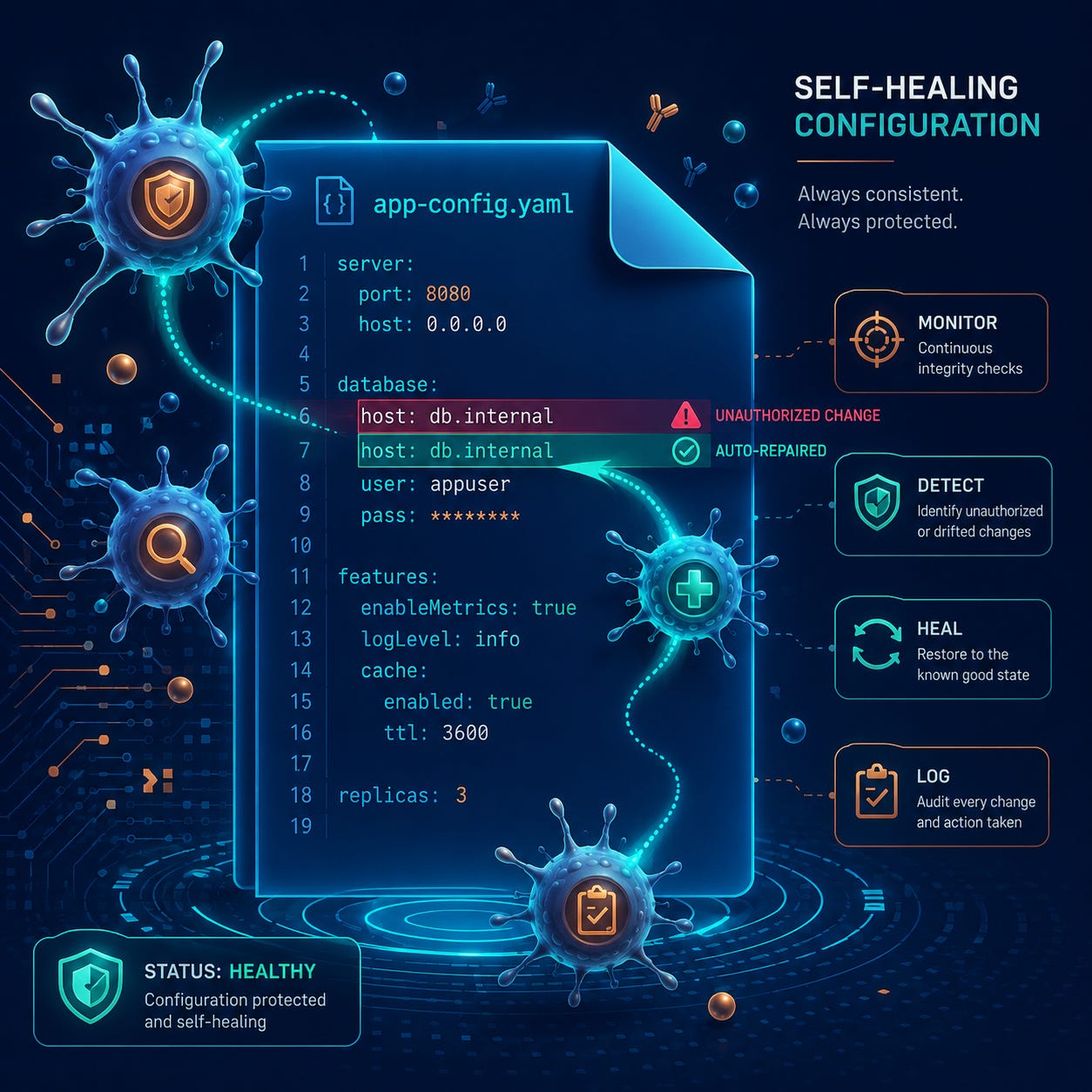
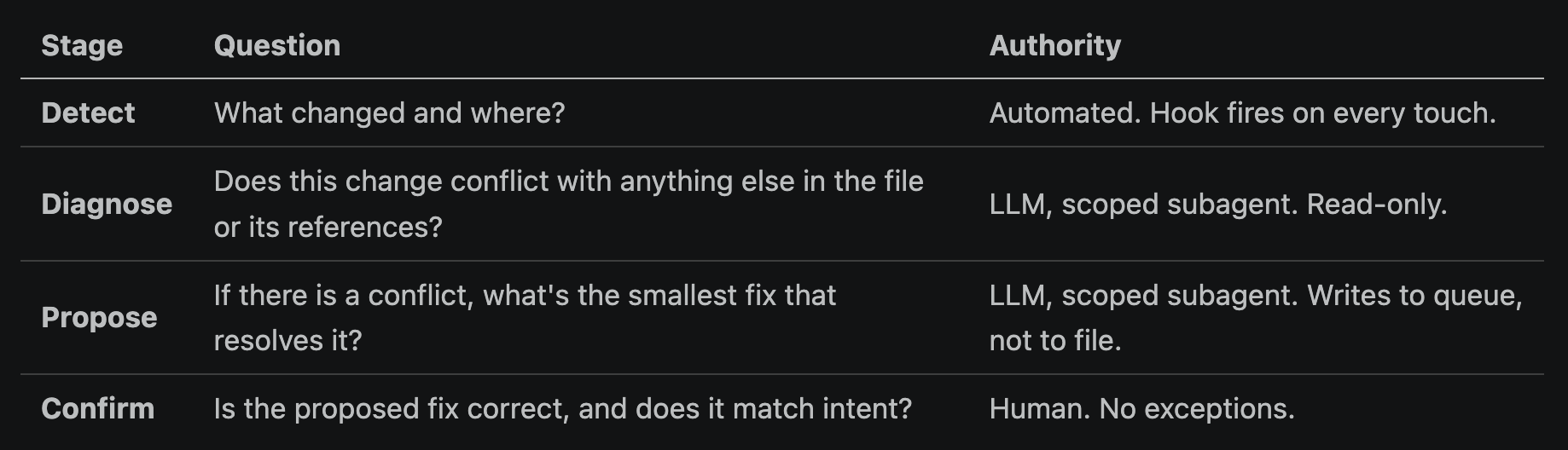
Stage 1: Detect. A PreToolUse hook fires every time Claude Code is about to modify CLAUDE.md. It captures the current state of the file, the proposed edit, and a hash of the surrounding section context.
Stage 2: Diagnose. The proposed edit is passed to a Claude subagent whose only job is to read the change in the context of the full file (and any referenced documents, like PERSONA.md or a rotation log). It returns a structured verdict: “no drift,” “soft drift” (a tone or wording inconsistency), or “hard drift” (a logical contradiction with another section).
Stage 3: Propose. If the diagnosis is “soft drift” or “hard drift,” the subagent proposes a fix. Not as a direct file write. As a unified diff with a written rationale, written to a queue file under .claude/drift/.
Stage 4: Confirm. Nothing in the CLAUDE.md gets auto-modified. Ever. The drift queue surfaces in my morning report. I approve, edit, or reject. Approved diffs apply atomically and log a “healing event” with timestamps.
The boundary that matters: structural changes always require human confirmation. The system can propose. It cannot enforce. This is the rule that makes the rest of it safe to run unattended.
Framework Extraction: The Detect → Diagnose → Propose → Confirm Loop
If you take only one thing from this Build Log, take this.
DDPC: Detect → Diagnose → Propose → Confirm. A four-stage pattern for letting an agent maintain its own configuration without giving the agent authority to change the rules it operates under.
Here is what each stage answers, in plain language:
The CFO translation: this is the same pattern as fraud detection at a bank. The system flags anomalies and proposes resolutions. A human authorizes the final write. The system gets to do 90% of the work. The human gets to keep authority over the 10% that determines whether the institution is still itself tomorrow.
The CTO translation: this is the pattern your ops team already uses for production database migrations. Auto-detect schema diffs, auto-generate the migration, never auto-apply. DDPC moves that same discipline to agent configuration, which is the new layer where most teams currently have zero governance.
Three things make DDPC durable over time:
The diagnostician is scoped, not general. It reads only the file under review and explicitly named references. No web, no shell, no other repos. Smaller surface, fewer hallucinations.
Proposals are diffs, not rewrites. A unified diff is reviewable in 30 seconds. A 200-line rewrite is not.
The queue is durable. Drift events live in a folder with timestamps. If I miss a morning report, the queue is still there tomorrow. Nothing gets silently dropped.
You can apply DDPC to any document that an agent reads as instruction: CLAUDE.md, PERSONA.md, style guides, rotation logs, prompt templates. The shape stays the same.
High-Level Implementation Overview
Here is the system on one page. Full code, the actual hook, the settings.json wiring, and the install script are in the paid section below.
Components:
A PreToolUse hook registered in
.claude/settings.jsonthat fires whenever Claude Code is about to write or edit any file matching**/CLAUDE.mdor other instruction documents.A drift detector Python script that captures the proposed change, builds the diagnostic prompt, and dispatches to the diagnostician subagent.
A diagnostician subagent (
.claude/agents/claude-md-diagnostician.md) with read-only file access, scoped to the file under review and a small whitelist of referenced documents.A drift queue at
.claude/drift/queue/holding one markdown file per pending healing event, each with the proposed diff, rationale, and a YAML frontmatter status flag.A morning report integration that surfaces the queue alongside my other agent outputs.
An apply script that takes an approved queue entry and applies the diff atomically, with a backup and a git commit tagged
chore(claude-md): drift fix [healing event].
Boundaries, restated:
Hooks only ever observe and propose. They never write to CLAUDE.md.
Diagnostician access is read-only and scoped.
Apply step requires explicit human confirmation through the queue.
Every healing event lands in git history with a traceable commit message.
I run this across all 15+ agents in my fleet. In the first three weeks it caught 14 drift events. Two were hard contradictions I would have shipped. Nine were soft tone drifts I would have lived with for months. Three were false positives I rejected and used to tighten the diagnostician prompt.
The full implementation lives below: the PreToolUse hook code, the drift detector logic, the propose-pause-confirm loop, the settings.json wiring, the install script, and the failure modes I hit along the way. Become a paid subscriber for $10/mo to read the rest of this Build Log and download the template ZIP.
Signal Stack
Five things worth knowing this week, with my one-line take on each.
↑ Anthropic Outcomes (May 7). Anthropic shipped Outcomes, a grader agent that evaluates production agent runs against example outputs you register up front. The shift from capability benchmarks to outcome benchmarks is overdue, and matches what every enterprise customer I’ve talked to in the last quarter has been asking for. Watch this become the default eval frame by year-end.
↓ Datadog: 60% of production LLM errors are rate limits (State of AI Engineering 2026). When an LLM call fails in production, six times in ten it is a provider rate-limit or capacity ceiling, not a model-quality problem (Datadog logged 8.4 million rate-limit errors in a single month). The translation: capacity planning for AI is not a future problem, it is a now problem. Most teams are budgeting for tokens and forgetting to budget for QPS.
👀 Google I/O 2026 governance gap (May 19). The Gemini 3.5 keynote shipped impressive capabilities (Spark agents, Android XR, on-device models) and almost nothing on enterprise governance. The gap between model capability and model governability is widening, not narrowing. CTOs evaluating frontier models should add a “what governance comes with this” column to the eval matrix.
↑ BCG 10-20-70 (refreshed 2026). BCG’s framework that AI value is 10% algorithm, 20% tech, 70% people and process change is getting cited in board decks again. The frame is right. The mistake teams make is treating the 70% as someone else’s job. It’s the architect’s job to design the 70% into the rollout.
👀 NTT DATA sovereign AI research (nearly 5,000 enterprise leaders surveyed, May 14). The sovereign AI conversation is shifting from “data residency” to “model authorship.” Enterprise leaders are starting to ask not just where their data lives, but who shaped the model that runs on it. This is a leading indicator for procurement criteria changes in late 2026.
