
Quality Gates for AI-Generated Code
and how you build them for yourself

Three weeks.
That is how long one agent drifted on my wife’s content system before I caught it. Not crashing. Drifting. The output was technically correct, passing every check I had written.
But it had started writing in a register that was not hers, slipping in punctuation she would never use, smoothing the edges off the exact phrasing that made her sound like her. I did not notice until I sat down to review a month of her published posts and felt something was wrong without being able to name it.

If you have deployed AI to write anything at scale (code, content, customer responses), you have probably had a version of this moment. The output is not wrong. It is subtly not theirs. And by the time someone names the problem, the drift has already compounded across dozens of artifacts.
So I shipped a linter for her voice. It runs as a PreToolUse hook in Claude Code: before every file write, it scans for the rules she refuses to break and blocks the write if it finds a violation. Twenty lines of Python, and it caught more drift in seven days than I caught in the previous three months of manual review.
The hook took 20 lines. The work of defining what counts as drift (which punctuation, which phrases, which rhythms violate a specific voice) took longer. That asymmetry is the whole point of this issue.
Why this matters now
On May 7, Anthropic shipped a feature called Outcomes: a separate grader agent that evaluates production agent runs against example outputs you register up front. Anthropic’s benchmark: up to a 10-percentage-point lift in task success compared to standard prompting. The week they announced it, I realized I had built the manual version months ago, a content-reviewer subagent sitting in this exact repo. The vendor finally productized what practitioners have been duct-taping together since the agent boom started.
AI Engineering is the practice of making AI systems work reliably in production: not the model layer, but everything around it. Tracing, evaluation, quality enforcement, drift detection. The same gap shows up in every enterprise I have advised: teams ship the AI demo, then discover they have no way to see what is happening once it goes live. I first wrote about that gap a year ago when I instrumented my own agents with Langfuse traces (19,000 views, still my most-read issue). I named the operational discipline it demands in March. This newsletter is about one specific practice within that discipline.
The three-gate system I am about to walk through was not designed in a lab. It was built for a real practitioner shipping real work, with zero tolerance for AI slop and a feedback loop tight enough to catch drift fast. The gates worked at that scale. Then I ported the same architecture onto a larger fleet where the scale problem is harder, the stakes are higher, and the drift is easier to miss.
The pattern I see in production: enterprises deploy AI to write code, content, customer responses, and discover six weeks in that quality is drifting in ways no one can quite name. The output is not wrong. It is subtly off. By the time someone notices, 40 posts have shipped that all sound a little less like the founder and a little more like a generic LLM. Or 40 PRs have merged that all use the same three patterns the model defaults to instead of the team’s own conventions.
My March 2026 reader poll surfaced the same pressure point. Of the 51 practitioners who responded, 39% named “consistent quality from AI-generated code” as their hardest open problem. It was the second-highest demand in the entire dataset.
Here is what actually works.
The failed first approach: review the output
My first instinct was the obvious one. Generate, then review. Catch issues at the end of the pipeline, before publication.
It fails for three reasons in production.
First, review does not scale. My content engine ships roughly 20 surfaces a week: 7 LinkedIn posts, 3 Substack notes, 1 newsletter, plus Twitter and Article variants. Behind those sit 18 autonomous agents that committed 63 times in the first two weeks of this month, scanning for signals, curating engagement, producing drafts, all without me touching the keyboard. Reading every output for quality drift is not a part-time job. It is an impossible one. Attention is the first thing that decays when you are tired. The same dynamic applies to AI-generated code: every team I have advised starts with “we’ll just review each PR carefully,” and quietly stops doing it within a month.
Second, review is the wrong layer. By the time the draft exists, the model has already committed to a register, a rhythm, a punctuation style. You are negotiating with output, not enforcing input. It is the difference between a code review and a compiler error: one catches things if the reviewer is sharp that day, the other refuses to ship anything that does not meet the contract.
Third, drift is invisible at the per-post level. One banned punctuation mark does not feel wrong. Forty across forty posts is a different voice. One PR with a generic exception-handling pattern is fine. Forty PRs all using the same generic pattern is a codebase that no longer reflects the team’s style. You only see it in aggregate, which means you only see it after damage.
You cannot review your way to consistency at scale. You enforce it at the write-time boundary, or you accept the drift.
The better solution: enforce at write time
Instead of reviewing drafts after they exist, I block writes that violate the rules before the draft hits disk.
In Claude Code this is a PreToolUse hook: code that runs before any tool execution. The model wants to call Write. The hook intercepts, checks the payload against my voice rules, and returns a non-zero exit code with the violation message if it finds one. The Write never happens. The model retries with cleaner output. No human in the loop, no reviewer fatigue, no negotiation.
The whole thing lives at .claude/hooks/check-em-dash.py, bound to Write and Edit, scoped to drafts/** and published/**. Operational files (content calendars, rotation logs, READMEs) are excluded. Same character, different role: punctuation in a table, voice violation in prose.
The discipline is not in the code. The discipline is in deciding what counts as a violation, codifying it as a rule a machine can apply, and refusing to negotiate when the model pushes back. The hook is the easy part. The rule file is the architecture.
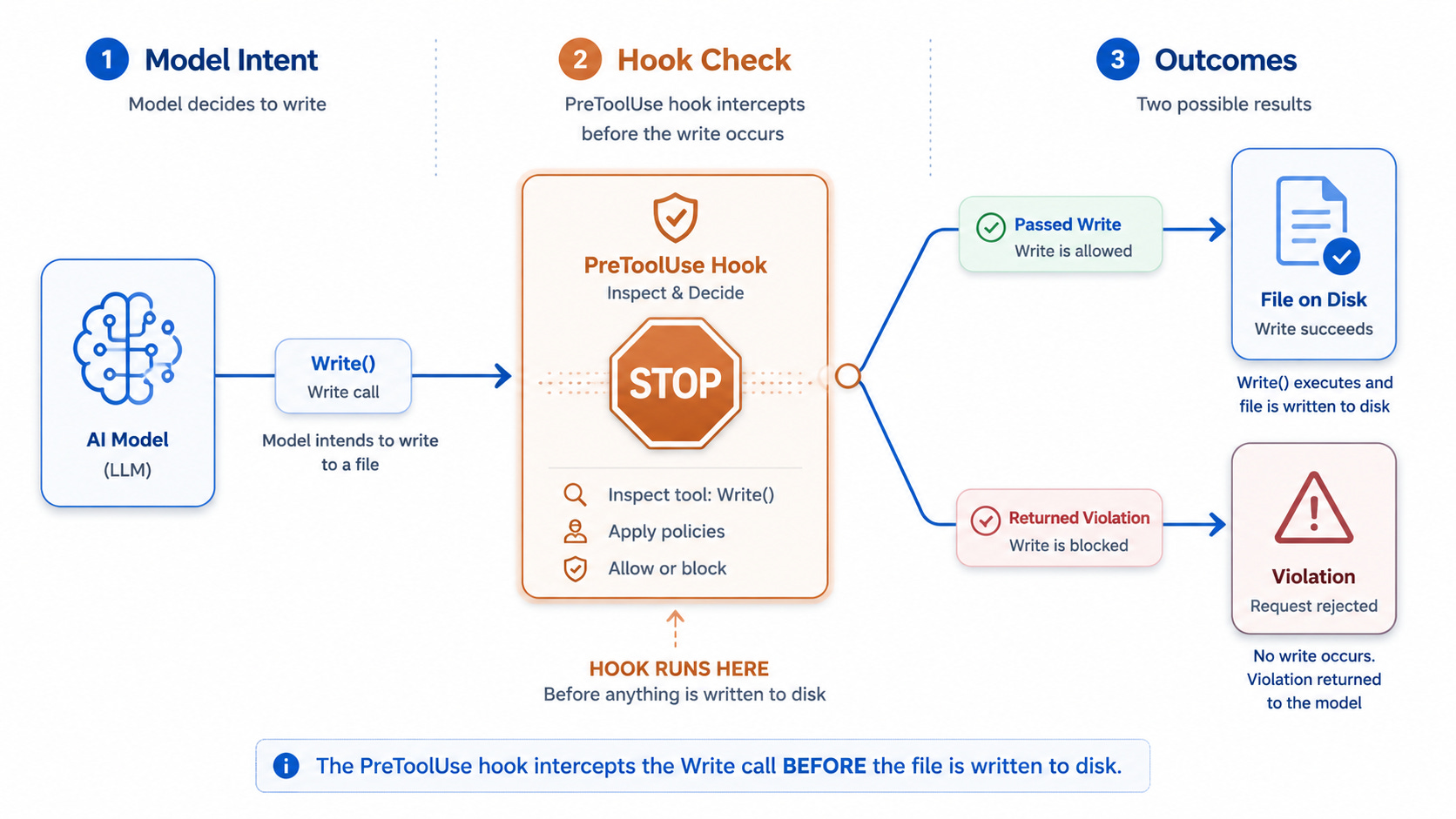
This is one gate. It catches one class of error. The hook alone would not be worth a newsletter, except it is the cleanest example of a much bigger pattern. Behind it sits a three-layer system I have been building for six months, and the other two layers are where most of the leverage lives.
The Voice Compiler: a three-gate system
I call it The Voice Compiler: it does what a compiler does, refuses to ship anything that does not meet the contract. Voice, in my case. Code, in yours. Three gates, catching progressively harder problems, each compensating for what the layer below misses.
Gate 1: PreToolUse hook (write-time, deterministic, syntactic)
v passed
Gate 2: content-reviewer (between-waves, LLM-graded, semantic)
v passed
Gate 3: monthly drift audit (30-day rolling, persona-anchored, structural)
Gate 1: PreToolUse hook (syntactic)
Catches: deterministic, regex-able violations. Banned punctuation. Banned phrases (”thrilled to share,” “in today’s fast-paced world”). Frontmatter schema breakage. Anything you can express as a string match, a regex, or a schema check.
Misses: anything semantic. The hook cannot tell that a paragraph is technically clean but reads like a McKinsey deck. It cannot tell that an exception handler is syntactically valid Python but violates your team’s “never catch bare Exception” convention if the rule isn’t encoded.
Why it works: runs at the write boundary, model retries until it complies. No human in the loop. Cost per violation caught: zero, because nothing gets written.
Gate 2: content-reviewer subagent (semantic)
Catches: voice register, missing signature phrases, save-worthiness gaps, hook strength, structural pattern adherence. This is my version of Outcomes. A separate Claude subagent reads each draft after the writer finishes, scores it on a five-dimensional rubric, and passes, conditionally passes, or fails it back. For code, the analog is a reviewer subagent that grades a PR against named conventions: “uses the team’s logging wrapper,” “follows the existing controller pattern,” “doesn’t introduce a new dependency without justification.”
The reviewer cannot edit, only score and explain. That separation matters: writers who grade their own work drift; reviewers who can rewrite become writers.
Misses: anything requiring a 30-day baseline. A single post slightly off register passes because no one rule fires hard enough. The drift is in the distribution, not in any one artifact.
Why it works: semantic checks need an LLM, not a regex. Runs between production waves so a failed wave does not poison the next.
Gate 3: monthly voice drift audit (structural)
Catches: distributional drift. The audit pulls 30 days of published content, compares it against PERSONA.md and voice-fundamentals.md, scores 0-10 across five dimensions, and recommends what to tighten. April 2026’s audit scored 4/10 and surfaced two failures: 97 occurrences of the banned punctuation mark across 16 of 26 published posts (despite the rule being documented in 3 reference files), and a visual-first shortfall against the monthly target. Both became new Gate 1 rules the following week. That mechanical hook? It is the direct output of an April Gate 3 finding.
Misses: speed. The audit is monthly. If this were your only layer, you would notice drift a month late.
Why it works: closes the loop. Gates 1 and 2 enforce rules. Gate 3 finds new rules to enforce. Without Gate 3, the first two layers stop catching new patterns and become brittle within a quarter.
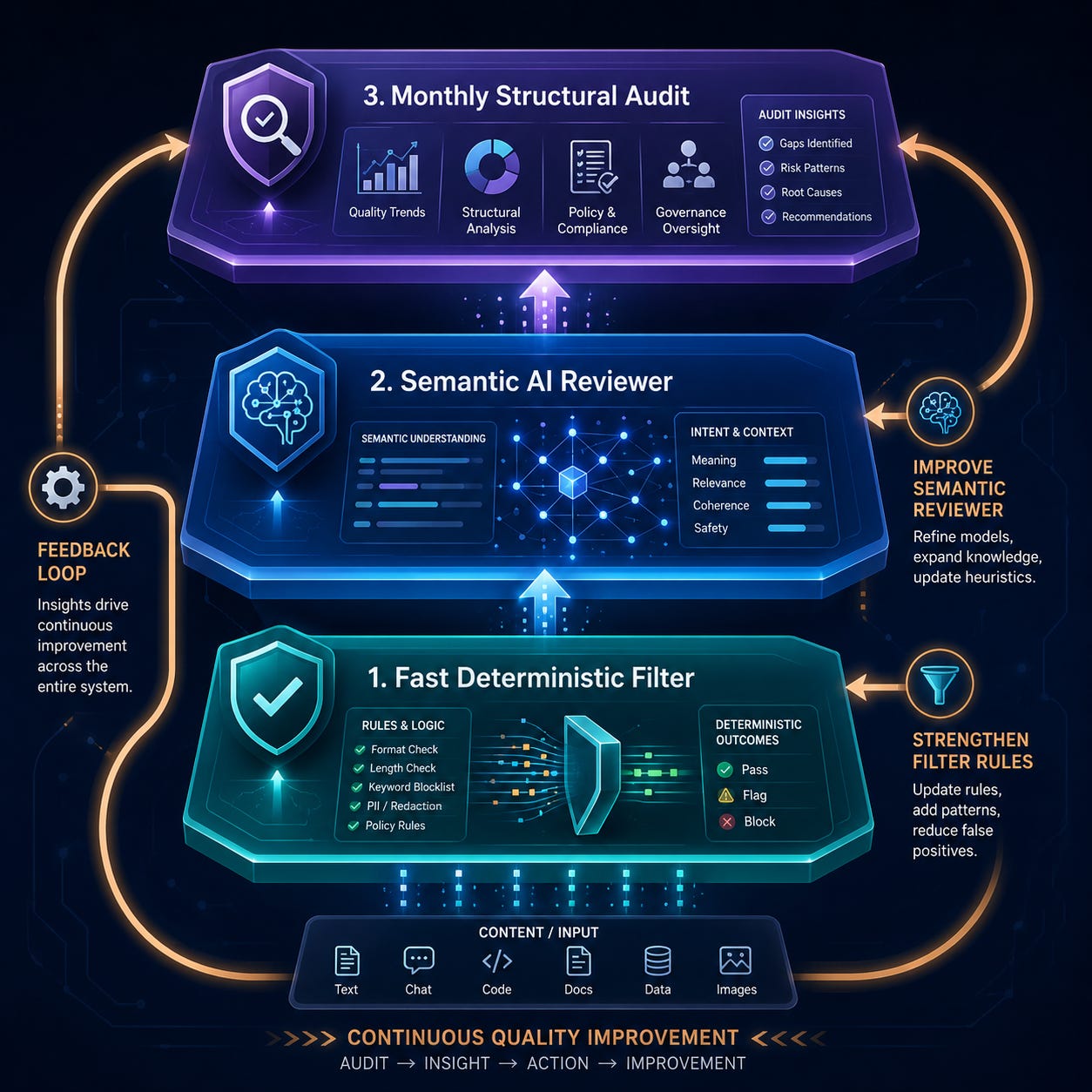
The translation for enterprise leaders: if you are deploying AI to produce anything at scale (code, content, support responses, internal docs), you need all three. Skip Gate 1 and you negotiate with output. Skip Gate 2 and semantic drift compounds quietly. Skip Gate 3 and you never learn what the first two are missing.
If you are making the case for AI quality enforcement internally, here is the framing that works: every quality gate you do not automate becomes a quality gate you negotiate. A sprint of plumbing locks in standards you would otherwise debate every week.
The layer most teams skip: observability
Three gates enforce quality. But enforcement without telemetry is like code without logging: you know something broke when a customer complains, not when it happens.
The piece connecting my three gates is Langfuse. Every Gate 2 review score flows into Langfuse as structured trace metadata: hook strength 8/10, voice register 7/10, save-worthiness 9/10. Over a month, I can see the distribution. If voice register averaged 8.2 in April and drops to 6.8 in May, the traces surface the drift before Gate 3’s monthly audit even runs.
The instrumentation I described a year ago was observation. This is the next step: using the observation layer to close the quality loop. Gate 1 blocks bad writes. Gate 2 scores drafts. Langfuse stores the scores. Gate 3 queries them to find what the first two miss. The observability layer is what turns three independent checkpoints into a compounding system.
For enterprise teams deploying agents at scale: if you do not have an observability layer for output quality, your enforcement gates are flying blind. You have checkpoints with no trend line. The critical move is instrumenting quality scores as trace metadata so you can query drift over time, not just catch violations in the moment.
What this still catches and what it does not
Honest assessment. The Voice Compiler catches most drift. It does not catch all drift.
It misses intentional irony that reads as anti-pattern. If you write a satirical post that uses banned phrases to make a point, the hook will block you. You have to either disable the hook for that file or accept that satire lives outside the system.
It misses drift in artifacts the gates do not see. If you ship a post directly from a draft on your phone without going through the Write tool path, no hook runs. The system protects the surface area it covers, not the surface area it does not.
It misses drift in the rules file itself. If voice-fundamentals.md slowly accretes contradictions, the gates will enforce the contradictions. The audit catches this eventually, but only eventually. Once a quarter I re-read the source-of-truth files against the original persona, not against current behavior.
The full Voice Compiler is the loop, not the gates
Three gates catch three classes of drift. The audit feeds new rules back into the gates. The gates feed clean output into the corpus the audit reads from next month. That feedback loop is the thing that compounds. Without it, you have a static rule set that decays. With it, the system learns what your standards actually are.
Compiler errors do not get debated in standup. Style preferences do.
What’s the messiest part of your current AI stack? The thing nobody talks about publicly? Hit reply.
Know someone building with AI or navigating AI transformation? Forward this issue, it takes 5 seconds.
Signal Stack
Five things worth your attention this week, with where I think they are heading.
↑ ClickHouse 26.4 ships native AI functions. (ClickHouse v26.4.1 release notes) Vector search, embedding generation, and LLM calls inline in SQL. The infrastructure layer for AI is collapsing into the database, and the analytics shops will get there before the AI-first stacks catch up.
↑ Anthropic’s Outcomes feature. (9to5Mac, May 7) Grader agent, up to 10-point lift on task success. This is Gate 2 of the system above, productized. Expect every agent platform to ship a version in 90 days.
👀 ServiceNow 9-second deletion incident. (Fortune, May 6) A misconfigured agent wiped a production table in nine seconds before a human could intervene. The blast radius problem is now a board-level conversation. Read-only modes and write-quotas on agents are no longer optional.
↓ NBER: 6,000 executives report no measurable AI productivity impact. (Fortune, Feb 2026) The headline is misleading. The data captures the deployment lag, not the technology ceiling. The CEOs reporting “no impact” are 18 months behind the ones reporting transformation.
👀 F5: 78% of enterprises now run inference on owned infrastructure. (Help Net Security on F5’s 2026 State of Application Strategy Report, May 7) Up from 41% a year ago. Average 7 models per enterprise. The “API-only” AI thesis is breaking down faster than vendors expected.
If you want every future Build Log like this, including the full hook code, the reviewer subagent prompt, and the repos, subscribe here.
Paid subscribers get the complete build: the full PreToolUse hook script, the content-reviewer subagent prompt I run between production waves, the monthly audit checklist, the registration steps for Claude Code, and the debugging notes from six months of running this in production. The concepts, architecture, and framework above are free. The working implementation is below.
