
How to get your Data AI-Ready?
Without a major overhaul

Reading time: 4 min
In this issue:
💡 The 4-pillar framework that prevents 90% of AI failures
🔥 Why $15M companies succeed where $100M enterprises fail
✅ Access to all the assets you need to get your data AI-Ready
I spent two hours this week with a group of CEOs and CTOs from Alberta’s fastest-growing tech companies. Their revenue ranged from $1M to $40M. Their AI experience ranged from zero to experimental. But they all shared one burning question: “How do we actually make AI work?”
The answer wasn’t what they expected. According to MIT’s 2025 State of AI in Business report, 95% of generative AI pilots fail to scale. The biggest problem isn’t that AI models aren’t capable enough; it’s that people and organizations simply don’t understand how to use the AI tools properly or how to design workflows that capture the benefits. Fortune
After building Snowflake’s GenAI practice from $0 to $22M in nine months, I’ve seen this pattern hundreds of times. Companies spend $200K on AI pilots, three months on model selection, and zero time on what actually matters: making their data AI-ready.

The Four Pillars for Data AI-Readiness
Here’s what I shared with those executives: the same framework that helped a $12M SaaS company achieve 80% ticket automation in four weeks while their $100M competitor was still building their data lakehouse.
The AI-Ready Data Framework consists of four non-negotiable pillars:
Accessibility: Can you actually GET your data programmatically? Not through manual CSV downloads, but via APIs and connectors. A $15M company connecting Zendesk via Fivetran in 30 minutes beats a Fortune 500 waiting 18 months for their perfect data platform.
Quality: Here’s the counterintuitive truth: you need “good enough,” not perfect. AI works with 80% complete data if it’s representative and bias-free. That missing 20% of phone numbers in your CRM? Probably fine. Missing contract end dates for churn prediction? That’s a problem.
Context: Gartner found that prioritizing semantics and metadata can increase GenAI model accuracy by up to 80% and reduce costs by up to 60%. Your “cust_stat” field means nothing to an AI. “Customer status (active, churned, paused)” with business definitions? Now you’re speaking its language.
Governance: PIPEDA violations can cost up to $100K per incident in Canada. But here’s what matters more: biased training data doesn’t just create lawsuits, it creates AI that actively harms your business.
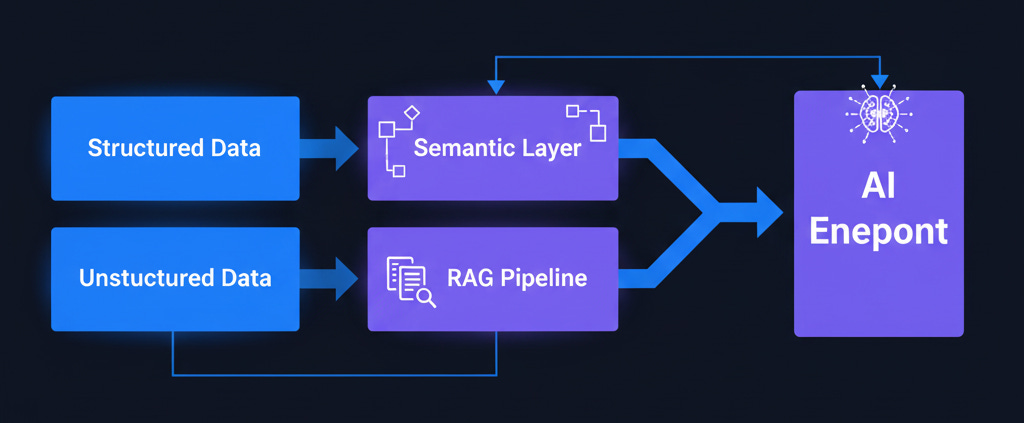
The Structured vs. Unstructured Distinction
This was the “aha moment” for half the room. Your approach to AI-ready data depends entirely on your data type:
Structured Data (CRM, ERP, spreadsheets): Add a semantic layer. Define what “revenue” means, what “closed deal” includes, when something counts as “churned.” Tools like dbt semantic layer or Cube handle this. Your Salesforce data doesn’t need to be perfect; it needs business context.
Unstructured Data (PDFs, emails, support tickets): Extract, chunk, vectorize, retrieve. The RAG (Retrieval-Augmented Generation) approach. Any amount of documents works; you don’t need 10,000 examples like with predictive analytics.
One CEO’s face lit up when he realized his 50,000 support tickets weren’t a data quality nightmare; they were an immediate AI opportunity.
The $2K Solution That Beat the $200K Pilot
Here’s what actually worked for that $15M SaaS company:
Month 1: Connected the top 3 data sources. Total cost: $2K/month (Fivetran + ClickHouse Cloud + OpenAI’s GPT-4o at $5 per million input tokens) Laozhang. Basic quality checks with Great Expectations (free). Documented 10 critical business terms in a Google Doc.
Month 2: Built a minimum viable pipeline for sales data. Connected to OpenAI API (15 minutes of setup, not 15 weeks). Deployed an AI sales email assistant as an internal pilot.
Month 3: Rolled out to all sales reps. Result: 15% faster deal closure, 30% larger deal sizes. Positive ROI in month 2.
Meanwhile, companies like Anthropic are pushing the boundaries with ClickHouse for their observability needs while developing Claude 4. Character.AI achieved 10x faster queries and 50% cost reduction for their AI workloads. The pattern is clear: start simple, prove value, then scale.
Your Monday Morning Test
📌 SAVE THIS: “Data readiness beats model sophistication. Every time.”
This principle alone will save you from joining the 95% failure club.
Here’s what you can do this week:
Audit your data using the scorecard from my workshop materials. Can you access it via API? Is it 80% complete? Does it have business context? Have you scanned for PII? If you answered yes to all four, you can start AI development THIS WEEK.
Pick your first use case wisely. Text analysis and RAG need the least data and deliver the fastest wins. Support ticket categorization, contract analysis, document search; these work with what you have today.
Download the complete workshop materials I created for the Alberta executives. You’ll get the full presentation, speaker notes, 90-day roadmap template, ROI calculation spreadsheet, and tool comparison matrix. Everything you need to transform your data from CSV chaos to AI-ready in 90 days.
Get the Complete AI Data Readiness Workshop Materials → (Includes slides, templates, and implementation guides)
The MIT research points to flawed enterprise integration as the core issue, not AI capability. FortuneLoris After watching a room full of growth-stage CEOs shift from AI anxiety to implementation clarity in two hours, I’m more convinced than ever: the companies that win with AI won’t be the ones with perfect data infrastructure.
They’ll be the ones who start with what they have, make it “AI-ready enough,” and iterate from there.
The real question isn’t whether your data is perfect. It’s whether you’ll still be in pilot purgatory when your competitor is already in production.
Try the framework. Let me know what unlocks for you.
This piece really made me think, particularly about the practical chalenges of data readiness. You've clearly identified the core issue beyond just model selection. How do you foresee these data accessibility principles applying to public sector initiatives, where legacy systems often prevail? Very insightful.